Leveraging Self-Supervised Learning for Enhanced Data Insights
 Jake Kitchiner
Jake Kitchiner
Read to find out how self-supervised learning and YouTube data are transforming machine learning pipelines, from speech recognition to content analytics.

Machine Learning via YouTube
Introduction
There are two reasons this feels the right time to write on this:
- OpenAI has just admitted (to no one's surprise), that they used YouTube for training their models.
- Machine Learning teams have requested collaborations for providing YouTube data to train models.
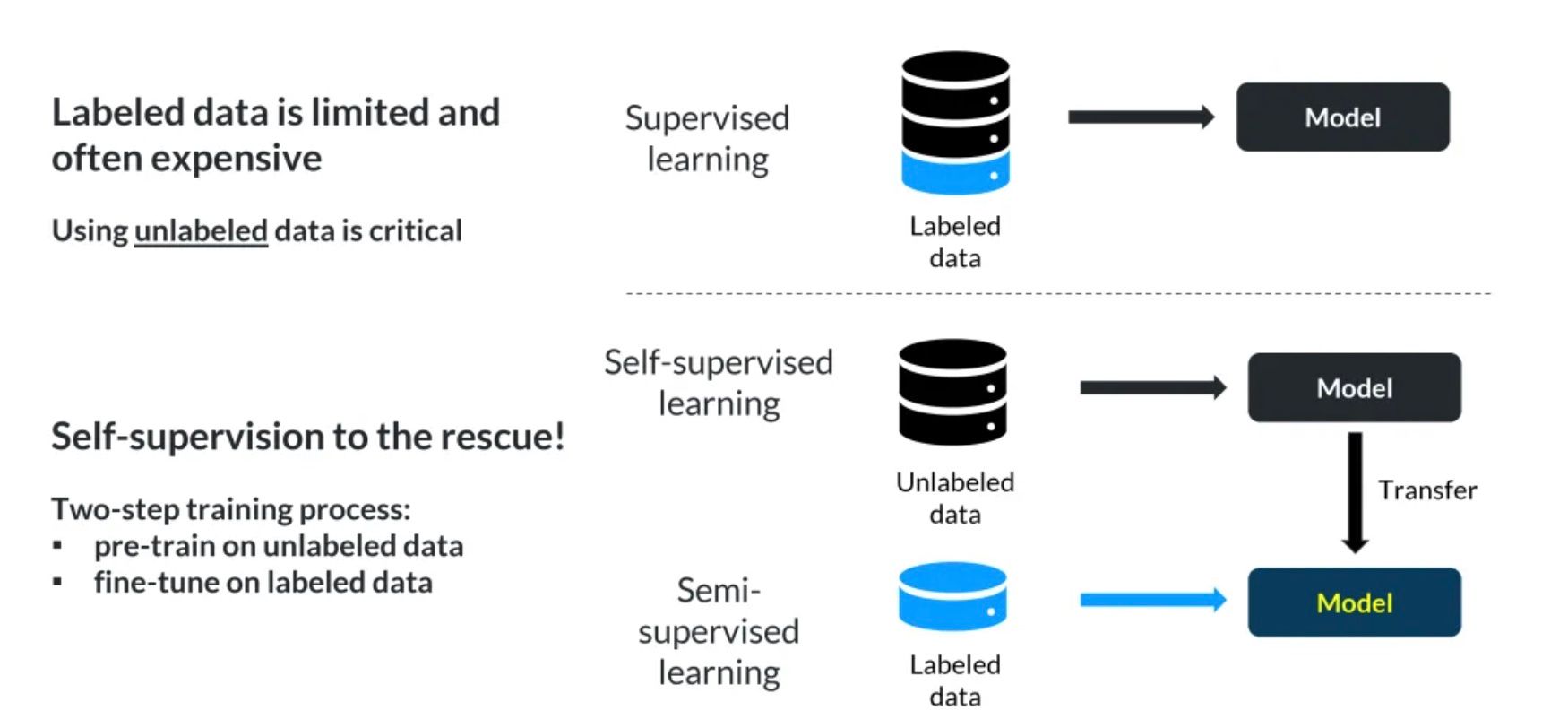
In the past 24 months, self-supervised learning (SSL) has emerged as a powerful tool in the arsenal of machine learning (ML) practitioners, offering a pathway to unlock deeper insights from unlabeled data, that previously seemed impossible, relying on mass-labeled data to achieve similar results.
This blog aims to give insights from a tech enthusiast, in to the realm of YouTube data analytics, drawing inspiration from the principles of SSL to illuminate how it can revolutionize data analysis in low-resource settings.If you're looking for ML solutions & big data sets for YouTube, our solutions page on this will probably be your best starting point.
Self-Supervised Learning: A Game-Changer
Traditional ML algorithms often rely on labeled data for training, a resource-intensive process that poses challenges in domains where labeled data is scarce. SSL, on the other hand, charts a different course by extracting patterns from unlabeled data, offering a more data-efficient approach to learning.
In the context of YouTube data analysis, SSL holds immense promise. By training SSL models on vast repositories of unlabelled channel data, researchers and marketers can uncover hidden patterns, trends, and audience preferences without the need for explicit labels. This opens up new avenues for comprehensive channel analytics and strategic decision-making.
Sample Efficiency: The Holy Grail of Data Analytics
One of the hallmark benefits of SSL is its ability to achieve remarkable cost and time efficiency. Unlike traditional approaches that require copious amounts of labeled data for optimal performance. SSL models can extract meaningful insights from unlabelled data with minimal supervision.
That begs the question - how do I obtain the SSL data?
YouTube is a great place to begin training models, but a wealth of YouTube channel URLs are needed to kickstart SSL experiments, as ML engineers need a data source to train the data.
This is where ChannelCrawler was able to help. ChannelCrawler has pre-labeled data that includes language, country, number of videos, ID & URL… which are all good places to start. By leveraging YouTube data, researchers can train SSL models to
- Train on voice data - Speech to text, accents etc.
- Build specialist subject knowledge - history, politics etc
- Discern intricate channel dynamics
- Identify emerging trends
- Tailor content strategies with unparalleled efficiency.
Pioneering the Future of Data Analytics
With the largest database of YouTuber channels in the world (at time of writing), Channelcrawler.com is positioned to enhance the way we extract insights from digital content. By embracing the principles of self-supervised learning and leveraging comprehensive datasets, ML engineers can leverage this data in ways that 5 years ago might not have been possible. If you want to see how this is being leveraged by major tech brands, then check out sites like Speechmatics.
If you’re looking for high volumes of data to train on, contact us today to discuss how we can help you get the right data to train your SSL models.